Webブラウザにはスクリーンリーダーと呼ばれる、サイトの内容を音声で読み上げる機能が実装されています。
この機能は目の不自由な方がブラウジングするのに役立つのですが、画像についてはサイトの作成者がラベル(代替テキスト)を付けていないと読み上げることができません。
Microsoftは同社のEdgeブラウザに対し、画像認識を利用して各画像に自動でラベル付けをおこなう機能を実装しました。

機械学習で画像を認識、自動でラベル付け
この機能はスクリーンリーダーを利用しているサイト内にラベルが付いていない画像を見つけると動作を開始します。
ラベルが付いていない画像に対し機械学習アルゴリズムを利用した画像認識をおこない、画像に適した説明文を自動生成し、スクリーンリーダーがその説明文を画像の代わりに読み上げます。

このアルゴリズムは完璧なものではなく、説明の質にもばらつきがありますが、Microsoftによると説明がないよりは何らかの説明があった方がスクリーンリーダーの利用者には良い場合が多いとのことです。
すでに日本語でも利用可能
この機能はすでにEdgeブラウザに実装されており、日本語でも利用可能です。
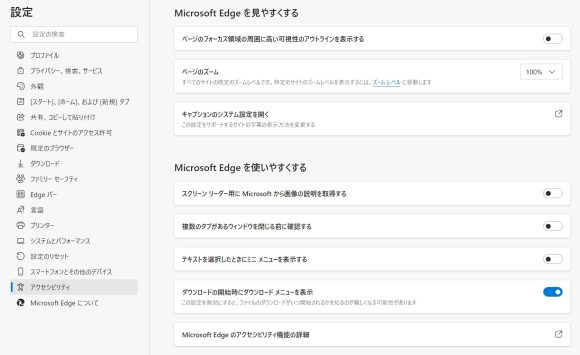
使用するには”edge://settings/accessibility”にアクセスし、「Microsoft Edge を使いやすくする」の「スクリーン リーダー用に Microsoft から画像の説明を取得する」を有効にします。
この機能を利用できる端末はWindows、Mac、Linuxで、AndroidやiOSは今のところ非対応です。
また、50×50ピクセルより小さい画像、非常に大きな画像、性的な画像や暴力的な画像などラベル付けがおこなわれない画像もあります。

Source: Microsoft Edge Blog via The Verge
(ハウザー)